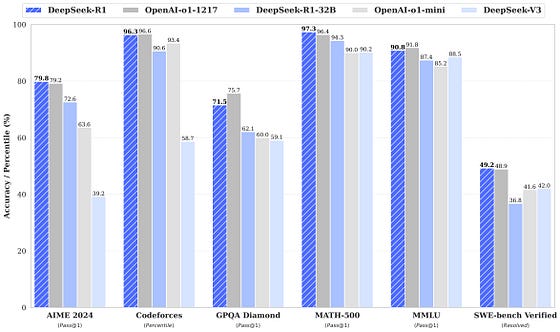
通过小型语言模型尽可能简单地解释 Transformer
在我们讨论 Transformers 并深入探讨键、查询、值、自注意力和多头注意力的复杂性(每个人都首先会涉及这些复杂性)之前,让我们仔细看看向量转换,它是包括 Transformers 在内的所有神经网络的核心,以及这里做了什么特别的事情。这将使所有其他部分都各就各位。
要理解 Transformer 神经网络架构,你必须首先了解向量变换或特征映射。然后了解向量化的概念(使用矩阵和 GPU 进行并行计算)。
如果我们通过谈论曲轴、活塞、调速器、进气阀等所有复杂的工程部件来解释蒸汽机的工作原理,人们就会忽略零件的整体情况。但如果我告诉你,小时候,詹姆斯·瓦特常常看着水壶烧开……
他看到盖子跳了起来,就试图用勺子把它按住。他发现自己无法把盖子按住,因为蒸汽一直把它往上推。“蒸汽很强大,”他自言自语道。“我想让蒸汽做一些有用的工作”:
这和我二年级课本上的解释完全一样。我敢打赌,只要有这张图片在脑海里,任何孩子都能很好地理解蒸汽机的原理。

自注意力机制是在 Transformer 出现之前发明和使用的。所以这不是这里唯一的重点,而是正如著名的标题所说“注意力就是你所需要的一切”,“你所需要的一切”。这是微妙的,很难首先得到。这个故事是关于 Transformer 神经网络的,它是一种像 TCP/IP 这样的软件工程壮举,而不是像反向传播算法这样的数学。这是一个仅将注意力部分堆叠和转换以创建可并行化的神经网络的故事,该神经网络可用于训练许多任务。正如 Andrew Karpathy 所说
Transformer 是一个很棒的神经网络架构,因为它是一个通用的可微分计算机。它同时具有以下特点:1)富有表现力(在前向传递中)2)可优化(通过反向传播+梯度下降)3)高效(高并行计算图)@karpathy on X
采取 1
让我们从一个关于老机器,支持向量机的简单故事开始,然后我们再逐步深入。
支持向量机(SVM)是一种非常流行的机器学习模型,用于对结构化数据进行分类。它之所以如此受欢迎,是因为它是第一个有效利用强大的向量变换概念的系统。
从一个简单的例子来看,这一点会更清楚。上图显示了在二维空间中绘制的两个类,分别为红色和蓝色。假设它们代表某个类的特征向量,比如说叶子的一个特征,用于分类它是否健康。
那么什么是特征呢?假设计算机需要区分猫和狗。因此它需要一些数字。这些数字可能是爪子的大小、牙齿的长度、头部与身体长度的比例或其他东西。这些代表主体特征的数字称为特征。一组这些数字组合在一起构成一个特征向量。
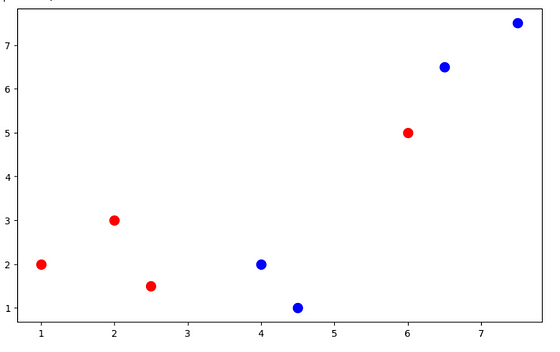
从图中可以看出,这些特征向量在这个二维空间中没有分离边界——(分离边界在二维空间中是一条线,在三维空间中是一个平面,在 N 维中是一个超平面 )。
我们不能画一条直线,一边是红点,一边是蓝点。最简单、最著名的线性回归算法无法区分这两个类别。
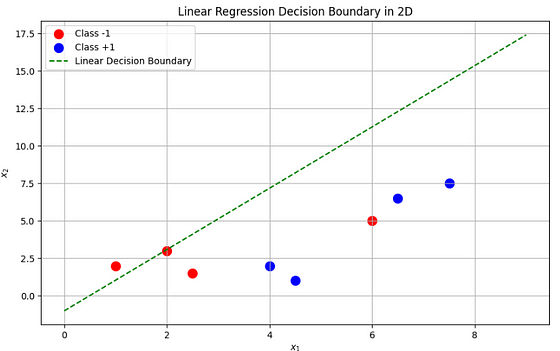
这时 SVM 就可以发挥作用了。
核心思想是,如果我们可以将这些向量转换或投影到更高维的空间,就有可能找到可以有效分离这些类别的超平面。
这是一个从 2D 特征空间转换为 6D 特征空间的简单方法。这是一个使用输入并将其转换为更高维度的简单函数。
#直接从2D转换为6D
# ------------------------- # 1)为2D点
定义多项式特征图φ(x) #x =(x1,x2) # ------------------------- def polynomial_phi(x): x1,x2 = x return [ 1.0, #常数项 math.sqrt(2)* x1, #√2 * x1 math.sqrt(2)* x2, #√2 * x2 x1** 2, #x1^2 x2** 2, #x2^2 math.sqrt(2)* x1 * x2 #√2 * x1 x2 ]
这里有一些注意事项。这些是使用的特定核,如多项式(如下)或高斯,它们有助于根据特征类型更好地对类别进行聚类,类似于照片编辑应用程序中用于转换(平滑、锐化等)图像的专用过滤器。
这些是多年来开发并经过实证测试的手工内核。如果您有兴趣,下面有关于 SVM 的更多详细信息。

简单的直觉是,将特征向量投射到更高维的特征空间有助于实现线性可分性。相似的特征(特征向量)可以被认为是“聚集在一起的”。
将特征向量转换为更高维特征空间的过程称为特征映射。
这种特征映射本质上是所有深度神经网络(包括 Transformer)的基础。然而,Transformer 中的特征映射不是通过手工编码的映射(如 SVM 中使用的多项式特征映射或高斯核),而是通过深度学习来学习的。
注意力机制是一种特定的特征映射,其中有序集合或标记序列中的每个标记及其所占据的位置以及该集合内的其他标记都会影响特征映射。
这意味着
“我游到了银行”和“我去了银行”虽然在用词上看起来非常相似,但注意力特征却完全不同。
因此假设 X 是输入集 = “我游到岸边,岸边是 ” → 训练好的 Transformer → AttentionKernel(X) → 预测词汇表中的下一个单词 → 可能会给出类似“陡峭”或“湿”的答案
而 Y 是另一个输入集 = “我去了银行,银行是” → 训练 Transformer → AttentionKernel(Y) → 预测词汇表中的下一个单词 → 可能会给出类似“开放”或“拥挤”之类的结果。
经过训练的 Transformer 拥有学习到的 AttentionKernel,就像我们在 SVM 中手动编码的多项式核一样。这就是 Transformer 所拥有的全部(请注意,大型语言模型具有突发行为,但我们现在不讨论这一点)
Transformer 架构的其余部分(例如多头注意力、前馈层、残差连接和层归一化)旨在使端到端训练稳定且高效。这有助于避免梯度爆炸或梯度消失等陷阱,并确保网络无需手动特征工程即可从数据中学习越来越丰富的特征映射。
回顾
- 特征映射或向量变换,其中将特征建模为 N 维向量并投影到 N+M 维(通常)有助于将“相似”向量或更准确地张量聚类在一起。
- 这些特征映射不是像 SVM 那样使用手工编码的核,而是通过深度学习来学习
- 特征映射学习基于自我注意力,其中函数依赖于序列中的所有标记,这些标记基于序列中的位置产生影响,以及它如何影响目标(稍后会详细介绍)
矢量化
这是一个软件工程术语,最好通过一些代码来说明。假设在 2D 空间中有一个包含源和目标的列表,我们需要找到它们之间的距离。通常的做法如下。
# 一些样本源和目标
sources = [( 1 , 2 ), ( 3 , 4 ), ( 5 , 6 )]
destinations = [( 7 , 8 ), ( 9 , 10 ), ( 11 , 12 )]
# 一个循环并进行计算的简单函数
import math
def calculate_distances_loop ( sources, destinations ):
distances = []
for i in range ( len (sources)):
x1, y1 = sources[i]
x2, y2 = destinations[i]
distance = math.sqrt((x2 - x1) ** 2 + (y2 - y1) ** 2 )
distances.append(distance)
return distances
distances_loop = calculate_distances_loop(sources, destinations)
print ( "Distances (Loop):" , distances_loop)
代码本身没有问题,但对于大量输入,以串行方式运行意味着我们处理速度很慢。软件工程师通常会将其以 map-reduce 形式拆分到多个线程或 CPU 等上,以便在多个 CPU 核心或分布式机器上并行化。
但还有另一种方法。这在我们使用的是 GPU 的情况下更为重要,因为 GPU 比 CPU 有数千个核心(但核心不像 CPU 那么通用,但非常适合乘法、加法等数学运算)。我们将它们转换为矩阵,并使用执行矩阵乘法的库来并行化
# 将这些转换为数组/矩阵
sources = [( 1 , 2 ), ( 3 , 4 ), ( 5 , 6 )]
destinations = [( 7 , 8 ), ( 9 , 10 ), ( 11 , 12 )]
sources = torch.tensor(sources, dtype=torch.float32)
destinations = torch.tensor(destinations, dtype=torch.float32)
import torch
def calculate_distances_torch ( sources, destinations ):
diff = destinations - sources # 计算差异矩阵
squared_diff = diff ** 2 # 逐元素平方
distances = torch.sqrt(torch. sum (squared_diff, dim= 1 ))
distances_torch = calculate_distances_torch(sources, destinations)
print ( "Distances (Torch,基于 Matmul 的):” , distances_torch)
所有神经网络本质上都是矩阵运算和矢量化的。但与 RNN 和 LSTM 甚至早期用于序列到序列映射的 CNN 相比,Transformers 是通过矢量化来实现 Attention 的,这使得它(在输入端)大规模并行,因此可扩展,最终导致像 ChatGPT 这样的 LLM。我们稍后会更详细地介绍这方面。
第二次
让我们为一个非常小的语言模型构建一个更简单的注意力模型,以便更好地理解这一点。这将更具技术性,需要一些神经网络背景才能理解。
单头注意力机制
Colab笔记本: https: //colab.research.google.com/drive/1NaD3PD6VtCQ2szvMJ2-Pa7ykhQ90HoaT#scrollTo=NzdcxKmqT7qi
上面给出的笔记本是自描述的。有了 Google 帐户并访问免费 T4 GPU,您就可以训练这个基本语言模型来执行基本的语言建模任务。
以下是使用训练示例中的十万行代码大致可获得的结果。我们的模型非常简陋,为了节省成本,我们只对一小部分数据进行训练。代码可以通过多种方式进行改进,例如通过整个数据集批量加载,而不是只取前十万行代码等。但为了提高可读性,请保持代码简单。
#测试生成函数
prompt = “Bloom住在一个大花园里”
#输出
生成的文本=Bloom住在一个大花园里,花园里有很多有趣的东西。有一天,莉莉看到一根大树枝,树枝上有很多有趣的朋友决定一起玩。他们非常高兴。他们很高兴他们有很多有趣的朋友,他们很高兴他们有很多有趣的朋友,他们很高兴他们有很多有趣的朋友,他们总是想和他们一起玩。他们很高兴他们有很多有趣的朋友,他们总是想和他们一起玩。他们非常高兴
关于训练数据集——Tiny Stories 的一句话。这本身似乎是一个有趣的数据集。这来自论文TinyStories:语言模型可以有多小,仍然可以说连贯的英语? (Ronen,Yuanzhi 2023)。它是专门为像我们这样的非常小的模型设计的。
“在本文中,我们介绍了 TinyStories,这是一个由 GPT-3.5 和 GPT-4 生成的合成短篇故事数据集,旨在仅包含大多数 3 至 4 岁儿童通常会理解的单词……我们的主要贡献是,我们展示了 TinyStories 可用于训练和评估更小的小型语言模型……或者具有更简单的架构(只有一个转换器块),但仍然可以生成一组多样化的流畅且一致的故事,这些故事可与更大、更复杂的模型生成的故事相媲美或更胜一筹……”
步骤 1:词汇和标记
给定一个文本输入序列,“The Cat walking on the”。第一步是
- 将文本转换为神经网络可以处理的数字。
- 这称为标记化
语言建模中的标记化
基于 Transformer 的语言建模神经网络的最后一层负责预测下一个单词(或 token)。
为了实现这一点,模型输出整个词汇表的概率分布,其中每个值代表特定标记成为下一个单词的可能性。
例如,如果我们的词汇表包含100 个单词,并且给定序列中的最后两个标记是"ball"和,则模型的最后一层可能会为输入“The Cat walking on the”"fence"产生如下所示的输出
[0.001,0.002,…,0.001, 0.89 ]
这里,0.89对应于最可能的下一个标记("fence"),而其他值表示替代标记的较低概率。
这就是为什么固定词汇表和预定义标记化至关重要——模型只能预测其词汇表中存在的单词或子词。
创建词汇表
大多数 LLM 使用一种称为字节对编码的算法,其中将单词拆分为组成高频项以创建此词汇表。有一个流行的库可用于训练和获取此词汇表和标记化,称为 SentencePiece,这就是我们使用https://github.com/google/sentencepiece/tree/master来创建词汇表的方法。
log.info("训练非上下文标记器") "训练非上下文标记器" )
spm.SentencePieceTrainer.Train(
input = "train.txt" , # 我们的训练数据
model_prefix= 'llama_like' ,
vocab_size=vocab_size,
model_type= 'bpe' ,
character_coverage= 1.0 ,
max_sentence_length= 2048 ,
treat_whitespace_as_suffix= True ,
split_digits= True # 这会强制拆分“123”->“1”、“2”、“3”
)
sp = spm.SentencePieceProcessor()
sp.load( "llama_like.model" )
tokens = sp.encode(test_sentence, out_type= str )
token_ids = sp.encode(test_sentence, out_type= int )
log.info( f"句子:{test_sentence} “)
log.info(f“令牌: {tokens} “)
log.info(f“令牌ID:{token_ids} “)
输出
test_sentence = "猫坐在栅栏上" "猫坐在栅栏上"
09 -Feb -25 08 : 00 : 43 - 训练非上下文标记器
09 -Feb -25 08 : 00 : 56 - 句子:猫坐在栅栏上
09 -Feb -25 08 : 00 : 56 - 标记:[ 'The','C',' at',' sat' ,' on ',' the','F','en ' , ' ce ' ] 09
-Feb -25 08 : 00 : 56 -标记ID :[ 60,1947,50,1134,56,16,1945,23,123 ]
第 2 步:嵌入
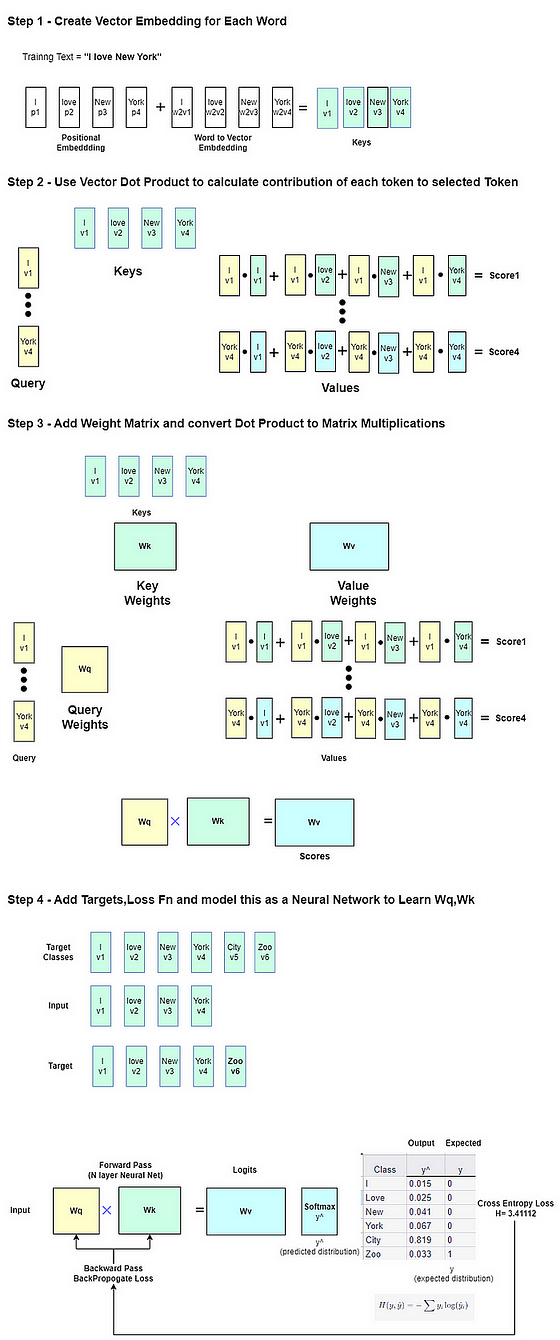
将标记的简单(学习到的)特征映射到更高维向量。
下一步类似于 SVM 将特征投影到更高维度。当应用于文本时,此过程称为嵌入。
在 Transformers 中,这是通过将 N 维权重向量与 token id 相乘来实现的。是的,就是这么简单。权重值是从训练中学习到的,使其成为学习到的特征映射。
由于论文《Attention is All You Need》使用术语d_model表示 N,因此我们也使用它。
# 定义一个线性层
token_embedding = nn.Embedding(
num_embeddings=vocab_size, embedding_dim=d_model)
# 在前向传递中使用该层
embedded_tokens = token_embedding(trimmed_input)
上面的代码使用了 PyTroch nn.Embedding 层。这本质上是一个线性层,但如果我们使用线性层,则每个标记都必须在 d_model dim 矩阵中进行独热编码并输入到线性层中。这个 nn.Embedding 在内部执行此查找,我们可以跳过独热编码直接输入转换后的标记。如果你不理解这一点,没关系,这是一个工程部分,对整体理解并不重要
该层与类似的Word2Vec的区别(没有太大区别)
这一层类似于我们从 word2vec 获得的静态嵌入;也就是说,它是非上下文的。
以前的 NLP 模型(如 word2vec)只使用经过训练的权重向量。然而,这有一个严重的限制,每个单词只能有一个嵌入向量,与上下文无关。
例如,“我吃了一个苹果”和“我买了一台苹果 Macbook”,使用 word2vec 等静态权重向量时,“苹果”一词的嵌入值将相同。因此,根据上下文,它不能聚类在橙子(其他水果)附近或(戴尔、其他计算机/公司)附近。实际上,它会在某个上下文中被错误地聚类。这就是您需要记住的全部内容。
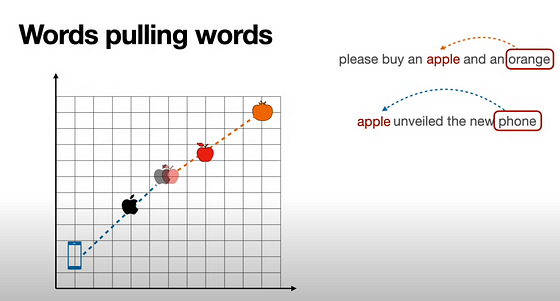
( Tomas Mikolov 等人撰写的Word2vec 论文“向量空间中词语表示的有效估计”)
步骤 3:自我注意力
这是将上下文嵌入思想实现为矩阵乘法和加法架构的地方。进行一系列线性变换以获得上下文嵌入 – 注意力机制。
这里要注意的一件重要事情是,Transformers 并没有引入 Attention 概念;它以一种可并行、高效的方式实现了 Attention,这种方式针对 GPU 和基于梯度下降的学习进行了优化。
这就是 Key、Query 和 Value 矩阵发挥作用的地方,事情变得复杂了。最好的理解技巧是不要将其与任何类比进行比较,例如键和值的映射查找等。将它们视为转换的混合,仅此而已。
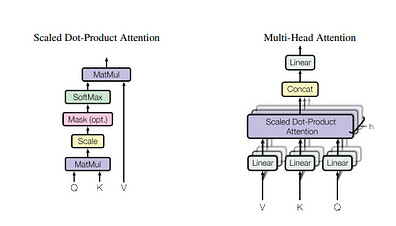

要理解这个公式,我们需要回顾一下过去,看看一些以前的研究成果。以下这些论文可以直接或间接地追溯到《注意力就是你需要的一切》这篇论文
2014 年:利用神经网络进行序列到序列学习( Sutskever 等人)
到 2014 年,深度神经网络 (DNN) 在图像识别和作为强大的通用函数逼近器方面的强大功能得到了广泛认可。然而,主要限制在于它过去仅适用于固定长度的输入并映射到固定长度的输出。
这篇论文《使用神经网络进行序列到序列学习》( Sutskever 等人)尝试使用 DNN 进行语言翻译等序列到序列的学习任务。
他们的做法是使用编码器从可变长度的输入句子中创建一个固定大小的向量(特征向量) 。然后,他们将其解码回目标序列,方法是使用这个固定大小的向量 (v)作为一个输入,将已经生成的序列作为另一个输入,并使用学习的概率生成器(类似于 LSTM 的线性层等效项)将其索引到固定长度的词汇表中。
下面的公式不需要完全理解,但将其与下一篇改进它的论文进行对比是有帮助的

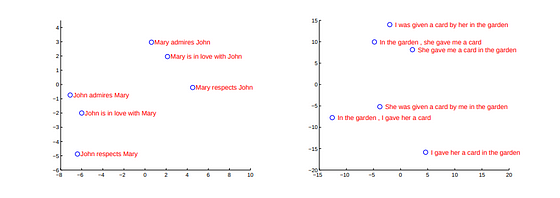
这实质上表明,使用学习到的转换将所有有序的标记集投影到更高维的特征向量,以一种方式对集合中的所有标记进行编码,并有助于学习可以生成目标序列的函数。
使用这种简单的学习映射投影到更高的维度有助于将相似的单词序列或句子聚类(因为当我们谈论向量时,接下来谈论的通常是点积和余弦相似度);如下面来自上述论文的图片所示。
2015:通过联合学习对齐和翻译实现神经机器翻译(Dzmitry Bahdanau 等人)
这是一篇引入了注意力概念的论文,尽管它并没有引起太多关注。然而,值得深入研究一下这篇论文,看看注意力概念的演变。


本文提出的是,用一种新方法来学习句子或序列的哪些部分对输出很重要,而不是之前最先进的将固定长度向量映射到可变长度的句子或序列的方法。
我们可以从这里看到注意力的概念正在慢慢发展
“在本文中,我们推测使用固定长度向量是提高这种基本编码器-解码器架构性能的瓶颈,并建议通过允许模型自动(软)搜索源句子中与预测目标词相关的部分来扩展这一点,而不必明确地将这些部分形成为硬段”
…允许模型自动(软)搜索源句子中与预测目标词相关的部分。
由于这里很好地捕捉到了粒状注意力的概念,我想从论文中引用几句话。
每次所提出的模型在翻译中生成一个单词时,它都会(软)搜索源句子中集中最相关信息的一组位置。
然后,模型根据与这些源位置相关的上下文向量和所有先前生成的目标词来预测目标词。…
.. 它不会尝试将整个输入句子编码为单个固定长度的向量。相反,它将输入句子编码为一系列向量,并在解码翻译时自适应地选择这些向量的子集。..
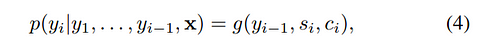
如果你还记得 2014 年论文中的公式,其中固定长度向量 v用于 下面给出的整个句子表示
与这里使用的 c(i)相比,它是句子中每个单词或标记的上下文向量(就像每个单词的注意力分数)
所有标记都使用算法转换为单独的特征向量(c_i),并从训练数据中学习非线性搜索函数(g),该函数可以为目标输出选择最合适的特征向量。
然后是 2015 年的一篇论文《基于注意力机制的神经机器翻译的有效方法》。Minh-Thang Luong 等人使用 RNN 再次给出了点积注意力机制
回到自我注意力
自注意力的理念与上述论文类似,即使用每个输入标记来计算其他每个输入标记的注意力分数,并使用缩放点积注意力,即 Luong 的 d_model 点积注意力机制。这是为了限制梯度下降过程中梯度变得过大,仅此而已。
但真正的突破是将注意力作为矩阵乘法。以下是Ashish Vaswani(主要作者之一)对此进行描述的视频摘录。
Transformer 是第一个通过简单线性层实现这一目标的神经网络,它不像之前的所有工作那样使用 RNN 或 CNN,这使得它能够通过矩阵乘法来实现注意力,这意味着并行(使用 GPU),这是一个巨大的瓶颈改进,并导致将训练扩展到我们现在所知道和使用的 LLM
另一个突破则更加微妙。它主要只使用这种机制,并去掉之前工作中的 LSTM、CNN 等所有内容
“我们问的问题是——为什么不使用注意力机制来进行表征?” Ashish Vaswani来源
“注意力就是你所需要的一切?”注意力加权表示可以表示整个序列,因此可以用于下游的进一步处理,例如生成下一个标记(具有因果注意力掩码的生成模型),而无需先前专门的网络(例如 RNN-LSTM 或 CNN)进行序列到序列的处理。
这是一个革命性的飞跃,从当时最先进的更复杂的网络(如 LSTM)或基于 CNN 的ByteNets,到仅使用堆叠的注意力块进行序列到序列的处理。
学习自注意力映射
由于注意力映射不是手工编码的内核,而且必须进行学习,因此在每个点添加一组权重,并最初随机初始化,然后像下面这样将这些权重与标记嵌入部分相乘,使其适合通过梯度下降进行学习。
在代码中(在自我注意类中)看到这一点更容易,因为解释这一点很令人困惑,你需要盯着它看很长时间才能明白。
# 初始三个随机权重矩阵 Q、K、V # 初始三个随机权重矩阵 Q、K、V
self.W_Q = nn.Linear (d_model, d_model, bias= False ) self.W_K = nn.Linear(d_model, d_model, bias= False ) self.W_V = nn.Linear(d_model, d_model, bias= False ) # 并在前向层使用它def forward ( self, x ): """ SingleHeadedAttention 的前向层 """ B, seq_len, d_model = x.shape # B 是批量大小,seq_len 是序列的长度,d_model 是嵌入大小(512) # torch.Size([1, 999, 512]) Q = self.W_Q(x) K = self.W_K(x) V = self.W_V(x) 注意力 = torch.matmul(Q,K.transpose(- 2,- 1))/ \ torch.sqrt(torch.tensor(d_model,dtype = torch.float32)) 注意力 = torch.softmax(注意力,dim = - 1) 分数 = torch.matmul(注意力,V)
为什么要使用这种特殊的注意力机制?如果你直接跳到本节,请参阅上面的部分,其中介绍了介绍该机制以及使用该机制的不同论文的历史记录(仅使用模型的缩放部分/除以平方根来减少梯度过大)。
请注意,与蒸汽机的离心调速器和进气阀等类似,还有一些工程部件,如位置编码和残差连接。这对于一般理解来说并不重要,但在实际实施中却至关重要。人们常说,Transformer 只是 ResNet 上的矢量化注意力块。
ResNet 基于残差连接/跳过连接的概念,非常简单。它只是将输入直接添加到输出,为梯度流动增加一个管道,并在另一管道被阻塞(梯度变得太低)时提供帮助。
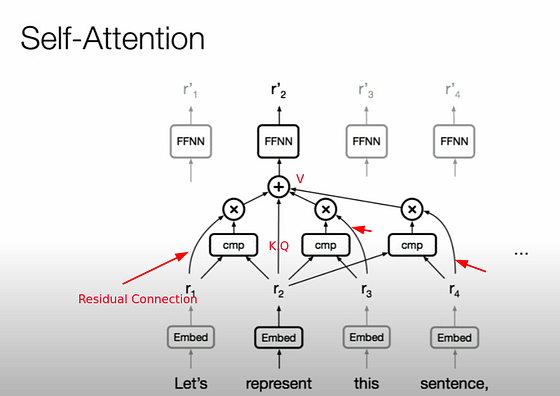
在我们的例子中,这是前向传递的最后一行
Q = self.W_Q ( x) self.W_Q (x) K = self.W_K ( x) V = self.W_V (x) tention = torch.matmul ( Q, K.transpose (- 2 , - 1 )) / \ torch.sqrt (torch.tensor ( d_model , dtype=torch.float32)) causal_mask = torch.triu ( torch.ones ( ( seq_len , seq_len), device=x.device), diagonal= 1). bool()tention =tention.masked_fill(causal_mask, float('-inf'))tention = torch.softmax ( attention , dim = - 1 ) score = torch.matmul ( attention , V ) #添加残差连接 out = x + score # 如果没有这个,模型输出就不好
步骤 4:通过线性层创建更多特征并投影到词汇维度
将注意力得分的输出进一步投影到几个线性层,以获得额外的特征,并有必要将其投影回词汇维度以进行损失计算
# 初始化线性层
prediction_layer1 = nn.Linear(d_model, vocab_size* 2 )
prediction_layer2 = nn.Linear(vocab_size* 2 , vocab_size)
layer_norm = nn.LayerNorm(vocab_size) # kast 维度是词汇大小
# 并在前馈路径中使用它们
embedded_tokens = token_embedding(trimmed_input)
# 形状保持 (batch_size, seq_len, d_model)
pos_embedded_tokens = pos_encoding(embedded_tokens)
# 获得注意力和分数
score,_ =tention_mod(pos_embedded_tokens)
# 预测下一个单词
hidden1 = prediction_layer1(score) # 投影到词汇表大小
logits = prediction_layer2(hidden1) # 通过几个线性层
# 添加层范数
logits = layer_norm(logits)
# 最后一个维度输出张量表示词汇量或类别数量。
# 因此,沿最后一个维度应用 softmax(dim=-1)
predicted_probs = torch.softmax(logits, dim=- 1 ) # 获取概率
# 获取预测词(token ID)
predicted_token_id = torch.argmax(predicted_probs, dim=- 1 )
# 计算损失# crossentropy 已经在内部执行 softmax
# 如果您的输入有 49 个 token,则您会预测接下来的 49 个 token。loss
= loss_function(
logits.reshape(- 1 , vocab_size),
target_labels.reshape(- 1 )
)
loss.backward()
前进道路的一个重要部分。
标签= input_ids.clone()
trimmed_input = input_ids[i][:- 1 ]
target_labels = labels[i][ 1 :]
我们从输入中删除最后一个单词,并将输入移位 1 以获取标签
对于输入集 [The, Cat, walk, on, the, Fence],神经网络的输入是[The, Cat, walk, on, the,],这些输入的目标是[ Cat, walk, on, the, Fence]
给定The ,它应该生成Cat;给定The Cat,它应该生成walking,以此类推,以此类推,进行损失计算。这样就不需要像另一个训练集那样单独添加标签了。训练标签可以从输入中生成,从而可以轻松地在大型文本数据集上进行训练。
因果掩蔽
我们遗漏了解释的一个较小的部分是因果掩蔽部分。请注意,与论文《Attention is All You Need》中 Transformer 的编码器-解码器层不同,我们正在对只有解码器层的类似 GPT 的架构进行建模。这并不重要。这两个块都很相似,但在论文中,只有解码器具有因果掩蔽,而编码器没有;大概对于像翻译这样的 NLP 任务来说,在编码器端查看整个输入序列是有意义的。如果您对此感到困惑,请将它们视为分层转换。
由于我们将其用作语言模型,因此它应该只能看到它之前生成的标记,即左侧的标记。由于输入 ID 是矩阵形式,因此右侧的标记成为矩阵的上三角部分(对角线上方);并且通过因果掩码将其清零。您可以通过移除掩码和训练来尝试这一点,并可以看到网络训练和输出无效。
Q = self.W_Q(x)
K = self.W_K(x)
V = self.W_V(x)
tention = torch.matmul(Q, K.transpose(-2, -1)) / \ 2 , - 1 )) / \
torch.sqrt(torch.tensor(d_model, dtype=torch.float32))
# 将掩码应用于注意力分数
# 为什么需要这样做;基本上,它允许模型只关注过去的标记,即在当前标记的左侧
,当你乘以 V
# 时,左侧变为下三角矩阵;右侧的未来标记是上三角矩阵
# 我们构建一个上三角掩码(设置为-inf),将注意力归零(下一个softmmax层将把它设置为零)
causal_mask = torch.triu(
torch.ones((seq_len,seq_len),device=x.device),diagonal= 1
)。bool ()
attention =tention.masked_fill(causal_mask,float('-inf'))
attention = torch.softmax(attention,dim=- 1)
score = torch.matmul(attention,V)
多头注意力机制
从笔记本中可以看出,输出效果不是很好。当然,我们的训练集也非常小。但通过使用更多的转换,我们可以改善这一点。这是多头注意力的核心直觉。
记住这一点;训练后的 K、Q 和 V 权重与 word2vec 权重一样固定不变。唯一变化的是输入序列的顺序。因此,为了通过这些学习到的过滤器为序列之间的交互创造更多机会,最好有一组不同的过滤器,而不是只有一个。也就是说,[K、Q、V] 值彼此不同(因为权重是随机初始化的,并且通过梯度下降进行训练也会使其保持不同),充当不同的学习过滤器集。这就是拥有多个注意力块的概念。
为了便于理解,在笔记本中,我没有通过矩阵乘法并行执行此操作并为头部数量添加额外的维度,而是按顺序执行此操作。
# 使用 SingleHeaded 添加多头注意力
# 添加一个线性层用于预测
num_heads= 2 # 在 T4 GPU 上工作
num_heads= 12 # 在 A100 GPU 上工作
multihead_attention = nn.ModuleList()
for _ in range (num_heads):
tention_mod = SingleHeadSelfAttention(d_model)
multihead_attention.append(attention_mod)
prediction_layer1 = nn.Linear(d_model*num_heads, vocab_size) # 因为我们正在连接头部输出
layer_norm1 = nn.LayerNorm(vocab_size)
prediction_layer2 = nn.Linear(vocab_size, vocab_size)
layer_norm2 = nn.LayerNorm(vocab_size) # 最后一个维度是词汇大小
多头顺序注意:Colab 笔记本多头注意 1
请注意,这款笔记本需要更多 GPU 内存,因为免费版 T4 GPU 内存(15 GB)不够。因此,您至少需要 Colab Pro(10 美元可获得 100 个 GPU 积分)才能运行它。
# 在前向传递中
embedded_tokens = token_embedding(trimmed_input)
# 形状保持 (batch_size, seq_len, d_model)
pos_embedded_tokens = pos_encoding(embedded_tokens)
# 初始化分数
# 初始化一个空列表来存储分数
head_outputs = []
# 从多头注意力中获取注意力和分数 - 我们正在以一种非常简单的方式#
实际上,这可以通过在矩阵中添加额外的 dim 来实现并行化,并且一次性完成
fortention_mod in multihead_attention:
score,_ =tention_mod(pos_embedded_tokens)
head_outputs.append(score)
# 将分数列表转换为单个
Multiheades 注意力模块的输出
# 测试生成函数
prompt = “Bloom 住在一个大花园里”
# 输出
07-Feb- 25 12 : 59 : 12 - 生成文本=Bloom 住在一个大花园里,脸上挂着
灿烂的笑容。她很高兴,并感谢妈妈帮助她。
她很高兴,拥抱了妈妈,说:“谢谢,妈妈。你真好。”但是,布朗尼和布朗尼小心翼翼地露出了脸上的灿烂笑容。她很高兴,并感谢妈妈帮助了爸爸妈妈。她拥抱了妈妈,说:“谢谢,再见。你真好。” Browpy
对于我们非常基本的系统来说,这还不错。下面是您对多头部分进行矢量化以便可以并行完成的方法
并行多头注意力机制:MultiHeadAttentionv2.ipynb
super().__init__() super ().__init__()
self.W_Q = nn.Linear(d_model, d_model, bias= False )
self.W_K = nn.Linear(d_model, d_model, bias= False )
self.W_V = nn.Linear(d_model, d_model, bias= False )
# 在前向传递中
# 为所有头部一起计算 Q、K、V,然后使用 head_dim 重塑,以便矩阵乘法可以并行完成所有操作
Q = self.W_Q(x).reshape(B, seq_len, self.num_heads, self.head_dim).permute( 0 , 2 , 1 , 3 ) # (B, num_heads, seq_len, head_dim)
K = self.W_K(x).reshape(B, seq_len, self.num_heads, self.head_dim).permute( 0 , 2 , 1 , 3 )
V = self.W_V(x).reshape(B, seq_len, self.num_heads, self.head_dim).permute( 0 , 2 , 1 , 3 )
# 其余与之前相同
# 计算缩放点积注意力
tention_scores = torch.matmul(Q, K.transpose(- 2 , - 1 )) / math.sqrt(self.head_dim)