DeepSeek 发布自己的 AI 图像生成器 Janus-Pro

德过去几天, eepSeek 的R-1模型在全球成为头条新闻。它是 OpenAI 的 o1 模型的开源且价格实惠的替代品。然而,甚至在 R-1 的热议平息之前,这家中国初创公司就推出了另一个名为Janus-Pro 的开源 AI 图像模型。
DeepSeek 表示,Janus-Pro 7B 在多个基准测试中的表现优于 OpenAI 的 Dall-E 3 和 Stable Diffusion。但它真的那么好吗?它是否名副其实,还是这只是另一个利用人工智能炒作的模型?
让我们来一探究竟。
什么是Janus-Pro?
简单来说,Janus-Pro是一个强大的AI模型,它可以理解图像和文本,还可以根据文本描述创建图像。
Janus-Pro 是 Janus 模型的增强版,旨在实现统一的多模态理解和生成。它具有更好的训练方法、更多的数据和更大的模型。它还能为短提示提供更稳定的输出,具有更好的视觉质量、更丰富的细节以及生成简单文本的能力。
请看下面的一些例子:
提示:一个美丽女孩的脸

较新的模型还具有更强大的文本渲染能力。
提示:一块清晰的黑板图像,表面干净,呈深绿色,中央用粗体白色粉笔字母准确清晰地写着“Hello”这个词。
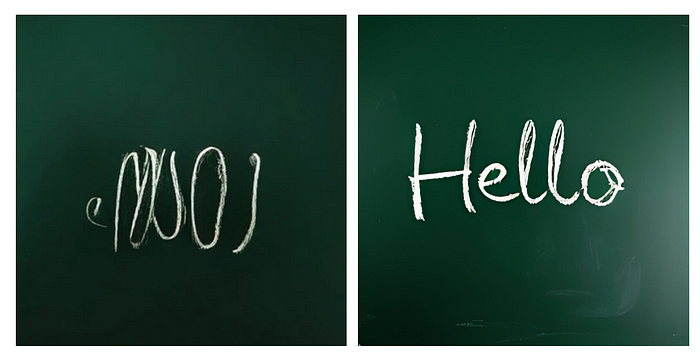
Janus-Pro系列包含10亿和70亿两种模型规模,体现了视觉编码解码方法的可扩展性,两种模型生成的图像分辨率均为384×384。
在商业许可方面,该模型可提供适用于学术和商业用途的宽松许可证。
Janus-Pro的技术细节
Janus-Pro 对多模态理解和视觉生成任务使用单独的视觉编码方法。这种设计旨在缓解这两个任务之间的冲突并提高整体性能。
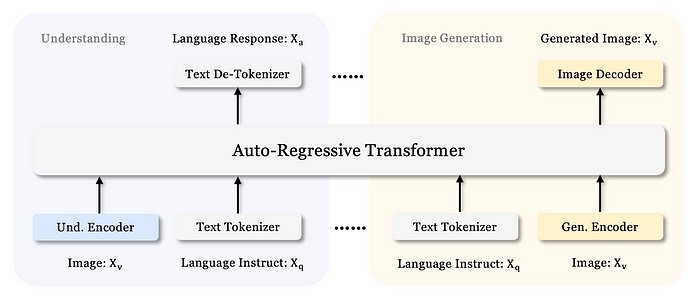
对于多模态理解,Janus-Pro 使用SigLIP 编码器从图像中提取高维语义特征,然后通过理解适配器将其映射到 LLM 的输入空间。
对于视觉生成,该模型使用VQ 标记器将图像转换为离散 ID,然后通过生成适配器将其映射到 LLM 的输入空间。
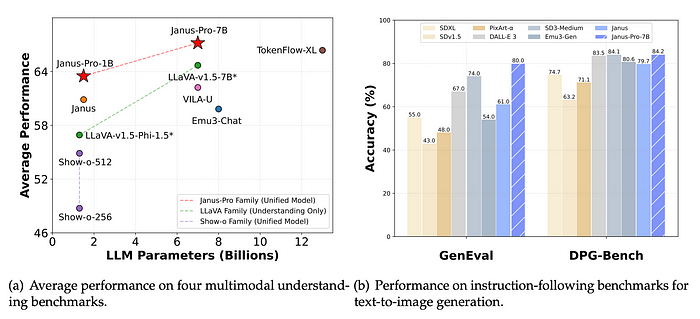
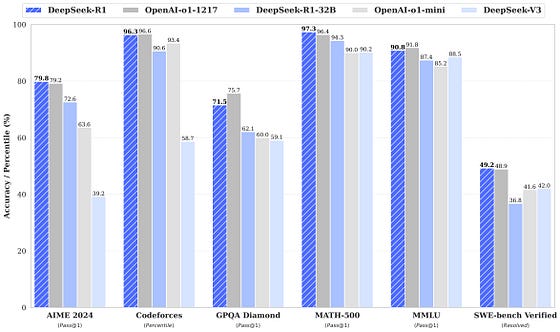
在文本到图像的指令跟踪中,Janus-Pro-7B 在GenEval 基准测试中的得分为 0.80 ,优于其他模型,例如 OpenAI 的 Dall-E 3 和 Stability AI 的 Stable Diffusion 3 Medium。
此外,Janus-Pro-7B 在DPG-Bench上获得了 84.19 的分数,超过了所有其他方法,并展示了其遵循文本到图像生成的密集指令的能力。
Janus-Pro 是否比 Dall-E 3 或稳定扩散更好?
根据 DeepSeek 的内部基准测试,Dall-E 3 和 Stable Diffusion 模型在 GenEval 和 DPG-Bench 基准测试中的得分均较低。
但由于样本图像的外观,我对这些信息持怀疑态度。证明这一点的最好方法是进行自己的测试。让我们看看下面的一些例子:
提示:一张绿色田野上一群红羊的照片。


提示:一位身材中等、身穿粉色薄纱连衣裙的 35 岁美女坐在埃菲尔铁塔前的地面上。柔和的灯光照亮了她的脸,她以香奈儿风格的巴黎为背景摆出一张照片。她披肩的棕色长发,蓬松的波浪形披散在一侧。


提示:一个小男孩拿着一块白板,上面写着“人工智能很棒!”


根据上述示例,Dall-E 3 的表现明显优于 Janus Pro。Janus Pro 输出的面部和身体比例明显不合适,文本渲染示例也表明它在这方面表现不佳。
话虽如此,我可能忽略了一些东西——可能需要特定的参数或微调才能改善结果。但是,使用默认设置,输出效果并不令人满意。
顺便说一句,如果你只是在寻找最好的 AI 图像生成器,我强烈建议使用Flux Labs AI中的 Flux Pro 1.1 Ultra 。它与我在本文封面图片中使用的工具相同。
Black Forest Labs 的 Flux 图像模型无疑是最好的。它是开放重量的,因此您可以使用自己的自定义图像对其进行微调。
如何访问 Janus-Pro?
DeepSeek 在 HuggingFace 上向公众发布了 Janus,以支持学术界和商业界更广泛、更多样化的研究。
- Janus-1.3B:拥抱脸链接
- JanusFlow-1.3B:Hugging Face链接
- Janus-Pro-1B:拥抱脸链接
- Janus-Pro-7B:拥抱脸链接
请注意,具有 70 亿个参数的 Janus-Pro 模型会占用近 15 GB 的内部存储器。
如果您不想在自己的硬件上运行该模型,您可以简单地在HuggingFace上运行 Gradio 演示。
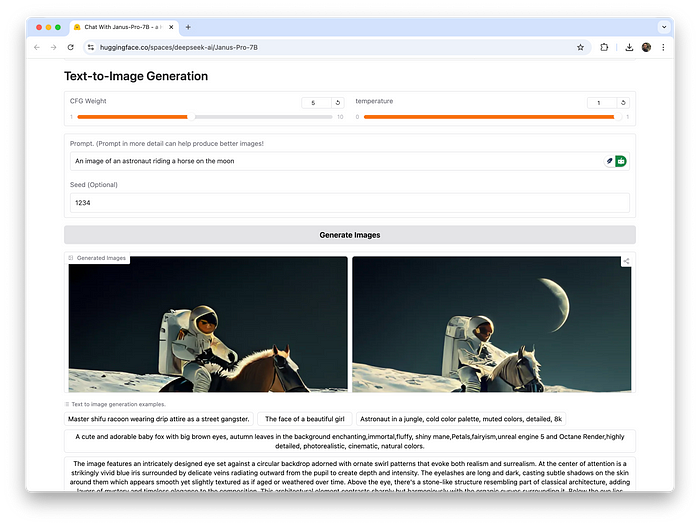
使用起来非常简单。只需描述您想要生成的图像,然后单击“生成图像”按钮。生成速度取决于同时使用该应用程序的用户数量。
您还可以通过上传图像并让 AI 进行解释来尝试多模式理解功能。以下是示例:
提示:解释一下这个 meme
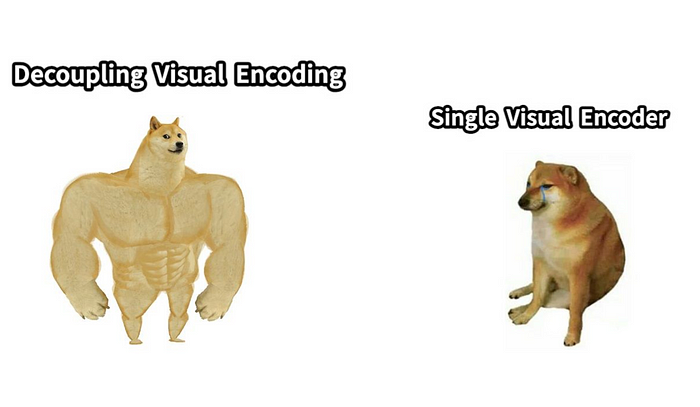
这张图片幽默地比较了两种视觉编码方法,使用了流行的“强壮的 Doge vs. Cheems”表情包格式。1.
**解耦视觉编码(强壮的 Doge)**:
- 图片左侧展示了一个肌肉发达的强壮的 Doge,代表了一种强大而稳健的视觉编码方法。这可能象征着一种更强大或更有效的视觉信息编码方法,例如深度学习模型或可以处理复杂视觉任务的高级神经网络。2
. **单一视觉编码器(Cheems)**:
- 图片右侧展示了一个体型较小、肌肉较弱的 Doge 坐着,代表一种更简单或功能较弱的视觉编码方法。这可能象征着一种传统或不太先进的方法,例如单个神经网络或基本编码方法,其性能可能不如更复杂的系统。
### 整体含义:
这个表情包幽默地对比了两种不同视觉编码方法的强度和效率。浅黄色的 Doge 代表一种更先进、更强大、更稳健的方法,而 Cheems 则代表一种更简单、更不强大的方法。这可以解读为对视觉编码技术演变的评论,与传统方法相比,深度学习和神经网络被视为更先进、更有效。
它非常准确,我认为它是自动添加字幕或为照片添加替代文本的绝佳工具。
对于开发人员来说,您可以下载该模型并在本地磁盘上运行它。以下是从文本生成图像的示例推理代码片段:
import os
import PIL.Image
import torch
import numpy as np
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
# specify the path to the model
model_path = "deepseek-ai/Janus-Pro-7B"
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True
)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
conversation = [
{
"role": "<|User|>",
"content": "A stunning princess from kabul in red, white traditional clothing, blue eyes, brown hair",
},
{"role": "<|Assistant|>", "content": ""},
]
sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
conversations=conversation,
sft_format=vl_chat_processor.sft_format,
system_prompt="",
)
prompt = sft_format + vl_chat_processor.image_start_tag
@torch.inference_mode()
def generate(
mmgpt: MultiModalityCausalLM,
vl_chat_processor: VLChatProcessor,
prompt: str,
temperature: float = 1,
parallel_size: int = 16,
cfg_weight: float = 5,
image_token_num_per_image: int = 576,
img_size: int = 384,
patch_size: int = 16,
):
input_ids = vl_chat_processor.tokenizer.encode(prompt)
input_ids = torch.LongTensor(input_ids)
tokens = torch.zeros((parallel_size*2, len(input_ids)), dtype=torch.int).cuda()
for i in range(parallel_size*2):
tokens[i, :] = input_ids
if i % 2 != 0:
tokens[i, 1:-1] = vl_chat_processor.pad_id
inputs_embeds = mmgpt.language_model.get_input_embeddings()(tokens)
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).cuda()
for i in range(image_token_num_per_image):
outputs = mmgpt.language_model.model(inputs_embeds=inputs_embeds, use_cache=True, past_key_values=outputs.past_key_values if i != 0 else None)
hidden_states = outputs.last_hidden_state
logits = mmgpt.gen_head(hidden_states[:, -1, :])
logit_cond = logits[0::2, :]
logit_uncond = logits[1::2, :]
logits = logit_uncond + cfg_weight * (logit_cond-logit_uncond)
probs = torch.softmax(logits / temperature, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
generated_tokens[:, i] = next_token.squeeze(dim=-1)
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
img_embeds = mmgpt.prepare_gen_img_embeds(next_token)
inputs_embeds = img_embeds.unsqueeze(dim=1)
dec = mmgpt.gen_vision_model.decode_code(generated_tokens.to(dtype=torch.int), shape=[parallel_size, 8, img_size//patch_size, img_size//patch_size])
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
visual_img = np.zeros((parallel_size, img_size, img_size, 3), dtype=np.uint8)
visual_img[:, :, :] = dec
os.makedirs('generated_samples', exist_ok=True)
for i in range(parallel_size):
save_path = os.path.join('generated_samples', "img_{}.jpg".format(i))
PIL.Image.fromarray(visual_img[i]).save(save_path)
generate(
vl_gpt,
vl_chat_processor,
prompt,
)
最后的想法
我理解人们对这款新图像模型的炒作。人们声称它是 Dall-E 3 的一个很好的替代品,但我不同意。我自己也试过 Janus-Pro,但图像质量并不像我想象的那么令人印象深刻。
一个关键的限制是输入分辨率受限于 384×384。此外,文本到图像生成的分辨率相对较低,再加上视觉标记器的重建损失,可能导致图像缺乏许多用户所期望的细节水平。
尽管如此,Janus-Pro 等开源模型的快速崛起表明 DeepSeek 已经将自己定位为 AI 竞赛中强大的颠覆者。尽管目前存在质量限制,但他们对可访问、开放创新的推动无疑让行业领导者争相适应。